Abstract
Multimodal generative models that can understand and generate across multiple modalities are dominated by autoregressive (AR) approaches, which process tokens sequentially from left to right, or top to bottom. These models jointly handle images, text, video, and audio for various tasks such as image captioning, question answering, and image generation. While AR models have been highly successful in the text domain, they have been found suboptimal for processing images, videos, and audio due to the high correlation between adjacent tokens which waste inference-time compute by separately predicting each one. In this work, we explore discrete diffusion models as a unified generative formulation in the joint text and image domain, building upon their recent success in the text domain alone. Discrete diffusion models offer several advantages over AR models, including improved control over quality versus diversity of generated samples, the ability to perform joint multimodal inpainting (across both text and image domains), and greater controllability in generation through guidance. Leveraging these benefits, we present the first Unified Multimodal Discrete Diffusion (UniDisc) model, which is capable of jointly processing text and images for a variety of downstream tasks. We compare UniDisc to multimodal AR models of similar capacity, demonstrating that UniDisc outperforms them in terms of both performance and inference-time compute, enhanced controllability, editability, inpainting, and flexible trade-off of inference time versus generation quality.

Build your sentence:
Model Response:
Demo Video
Demo Video: UniDisc can jointly inpaint images and text pairs. Please checkout the demo on our GitHub.
UniDisc Overview

UniDisc is a unified multimodal discrete diffusion model that can jointly process and generate text and images. First, each modality is converted into a sequnece of discrete tokens and we randomly replace a subset of these tokens with the [MASK] token according to a noise schedule and denoted in the figure with grey boxes. We jointly denoise the image and text and supervise with a weighted cross-entropy loss. At inference time we begin with a set of [MASK] tokens and iteratively unmask tokens.
UniDisc Training Scaling Laws
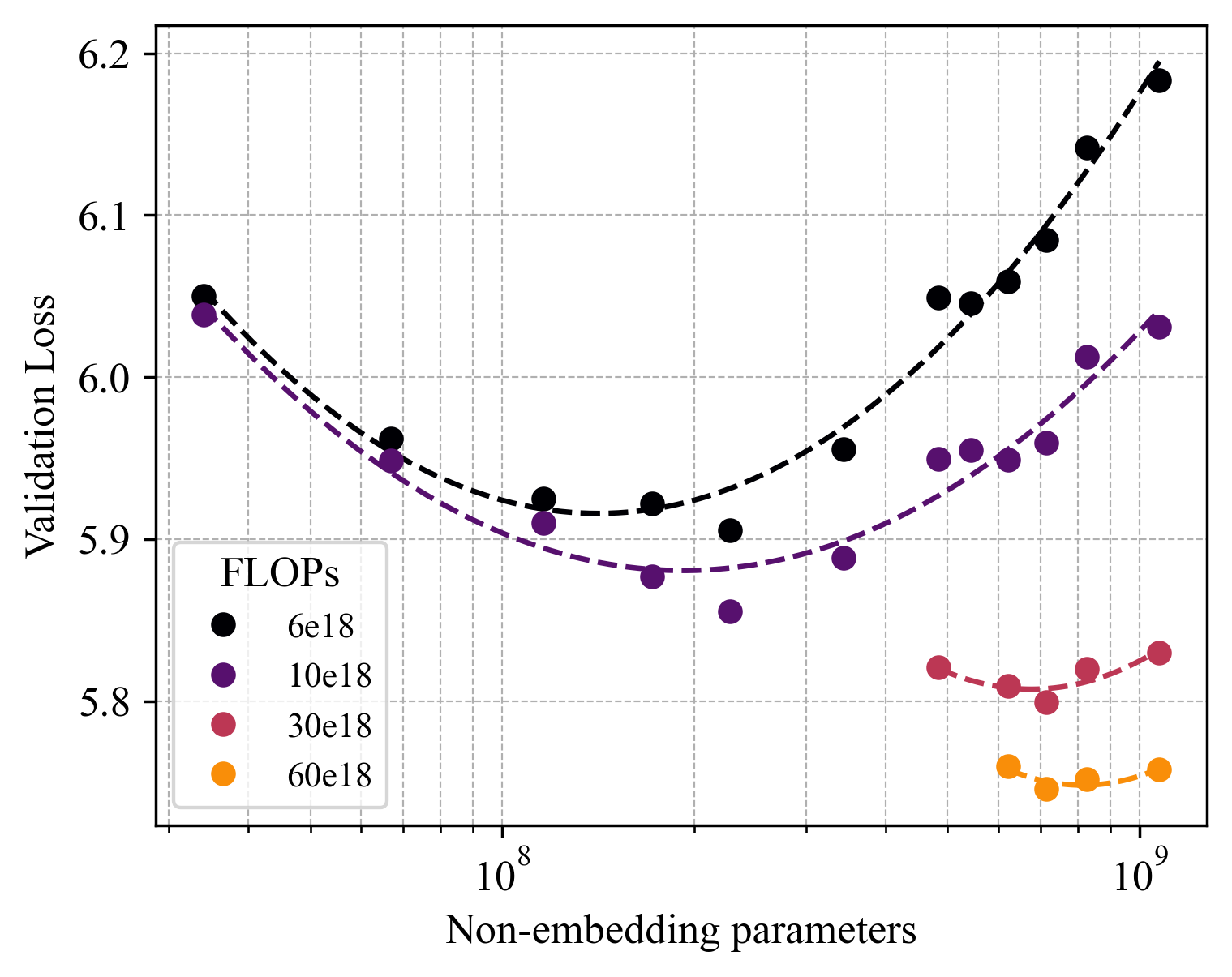
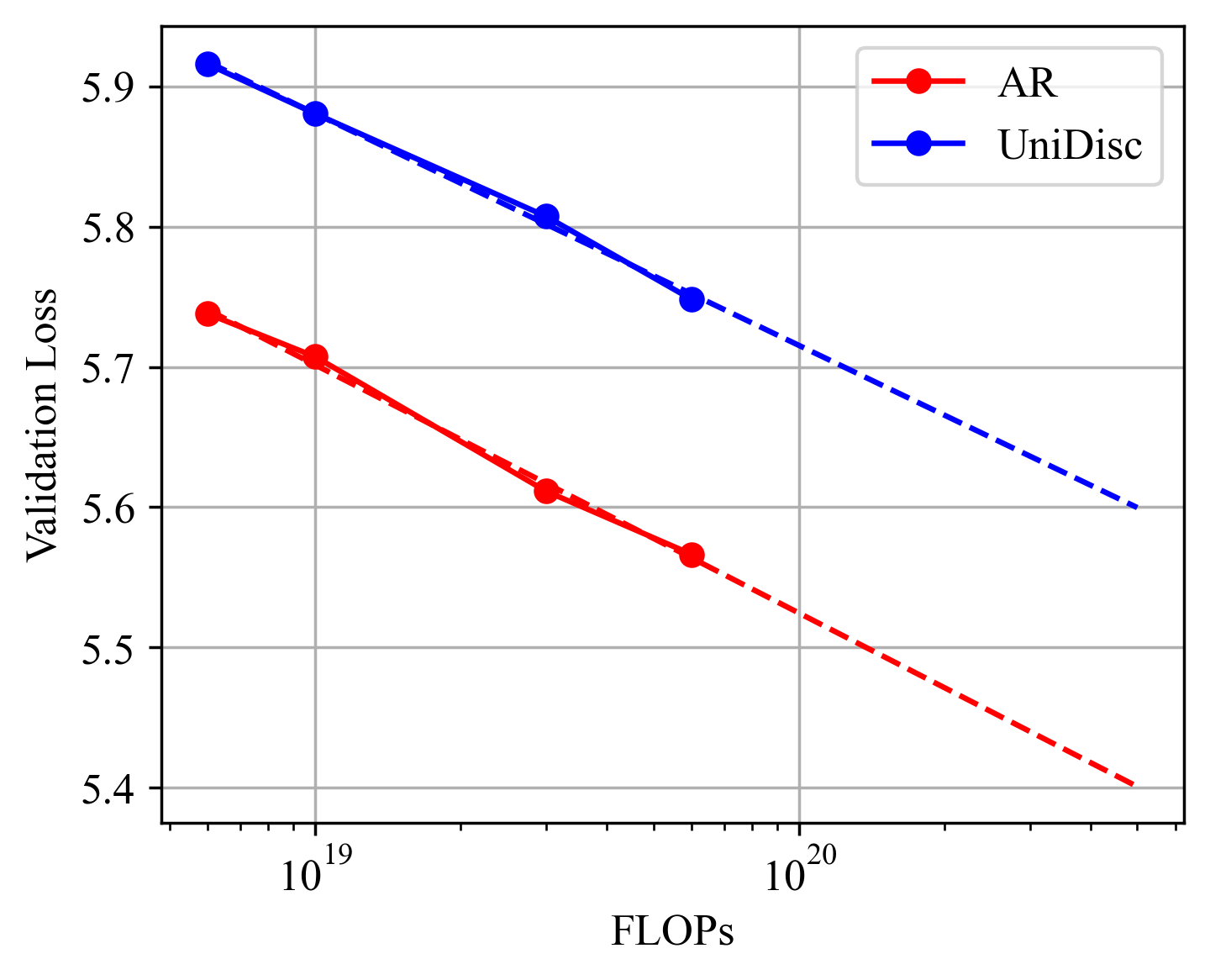
Scaling Analysis for AR and UniDisc models: (Left) IsoFLOP curves for UniDisc, plotting varying model size for a fixed FLOP budget. (Right) Estimating optimal parameter size for each budget - minima of fitted parabola, we plot scaling laws for both AR and UniDisc. We find 13.2x more compute is required for UniDisc to achieve the same overall loss as AR.
UniDisc vs. Autoregressive at Inference
UniDisc can generate images with a lot lesser forward passes than AR models.
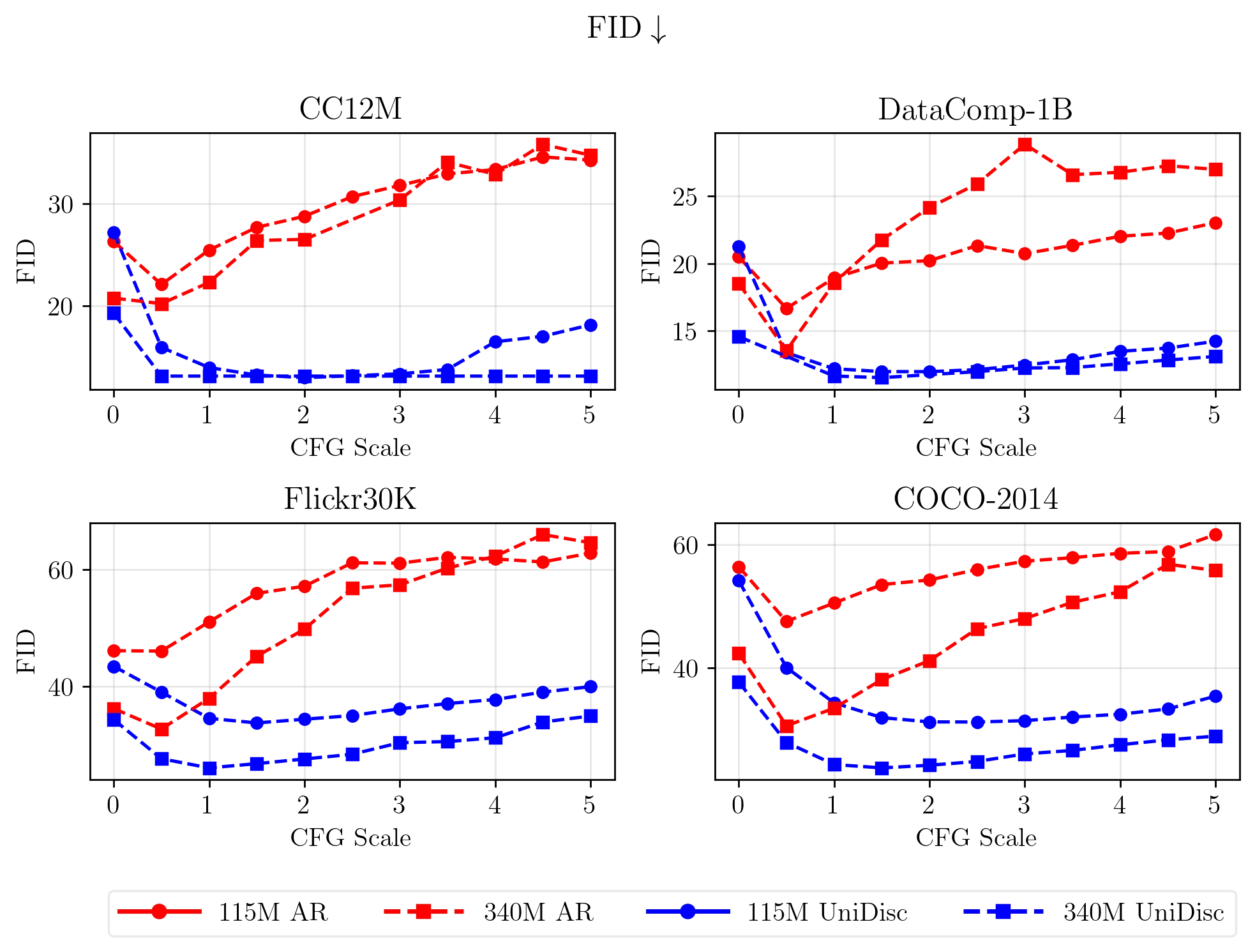
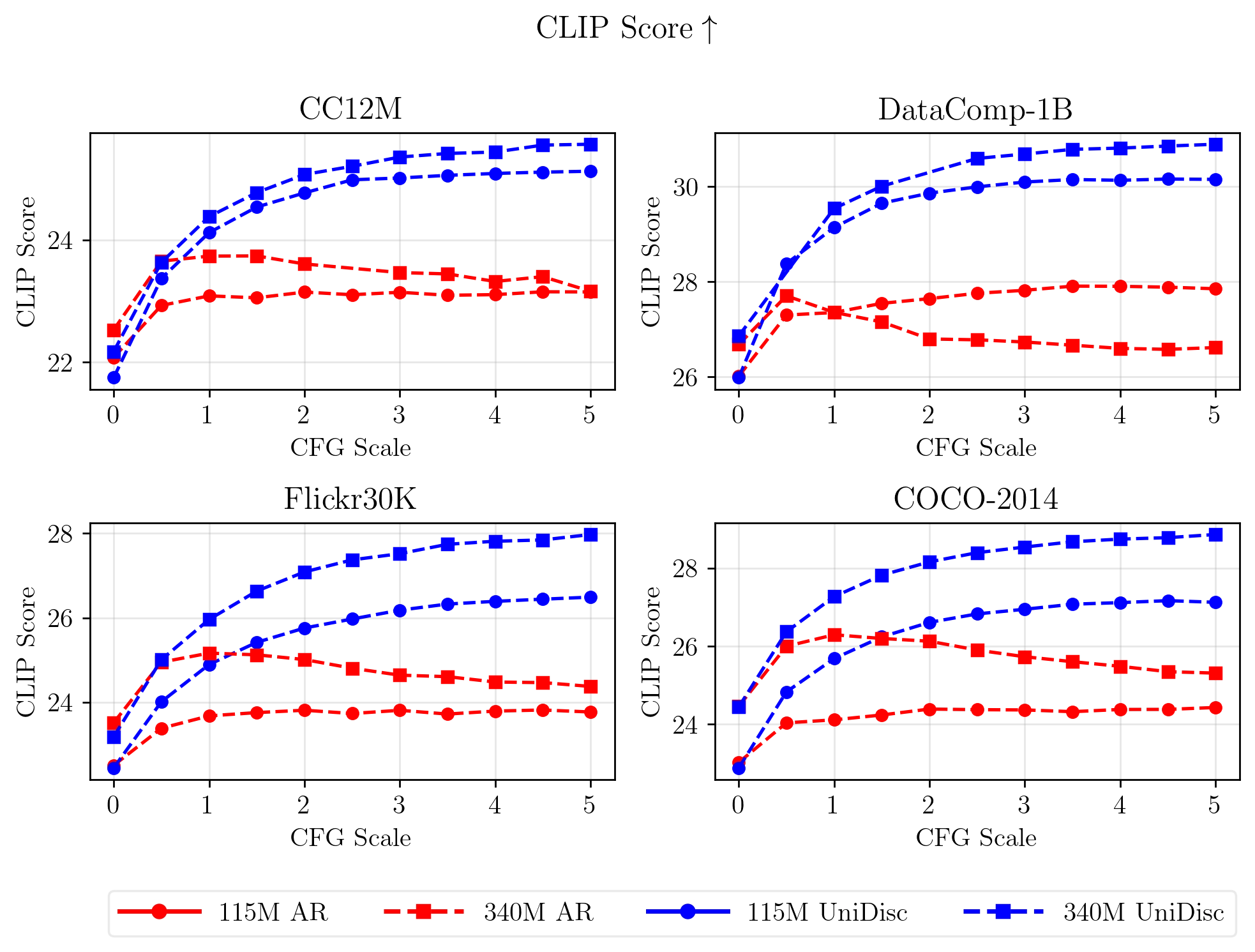
Conditional generation results for both FID and CLIP metrics, across a range of CFG values.} We find that AR is more sensitive to the CFG weighting, with a narrower optimal range. We find UniDisc achieves better FiD and CLIP score than Unifiied Autoregressive models such as Chameleon.
Zero-shot Multimodal Editing with UniDisc
Zero-shot Multimodal Editing Results

UniDisc can automatically improve a user provided image and caption. We adopt a best-of-n sampling strategy with n distinct noise masks. We unroll each generation until completion and use the model's own likelihood to determine select the best generation.
We augment real images by overlaying random objects from the COCO dataset. Similarly, we augment captions by asking an LLM to generate purposely incorrect variations. We then randomly mask the image and text inputs and unmask as described above, automatically removing these undesired image artifacts and generating the correct caption. There is no human intervention or masking in any examples. In the final row, we fix the text prompt, and only allow updates to the image.
Generation Analysis

Intermediate Steps during Joint Infilling of Image and Text. UniDisc jointly infills both image and text during generation.
Uniform Concept Generation
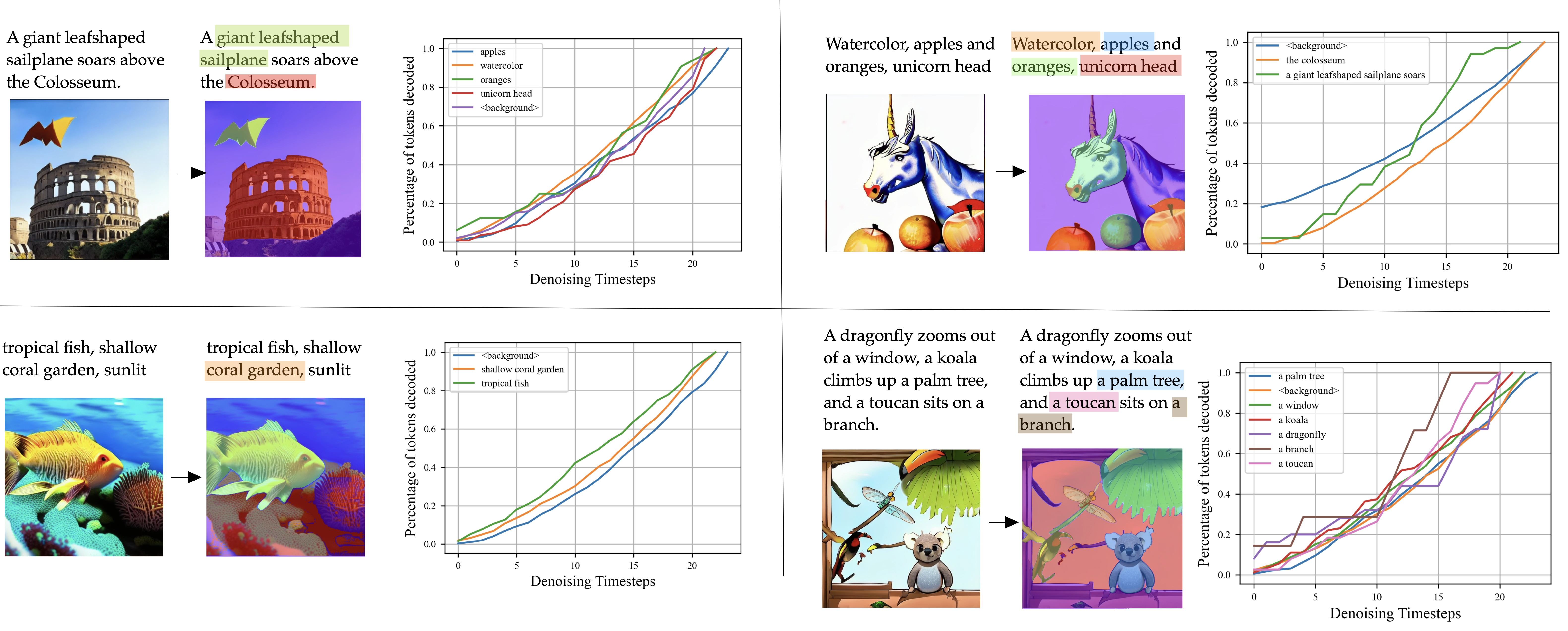
To quantitatively analyze the generation order, we use an language-grounded segmentation model (Grounded SAM 2) to segment the image given the text prompt. We then record the order of token decoding when using confidence-based sampling and plot the progression of each region. We observe that the model generates uniformly over concepts and modalities. In AR this is not possible as the model must generate in a specific order (e.g., text first, then raster-order), and thus the model cannot jointly reason over modalities and multiple parts of the image.
Classifier-Free Guidance Analysis
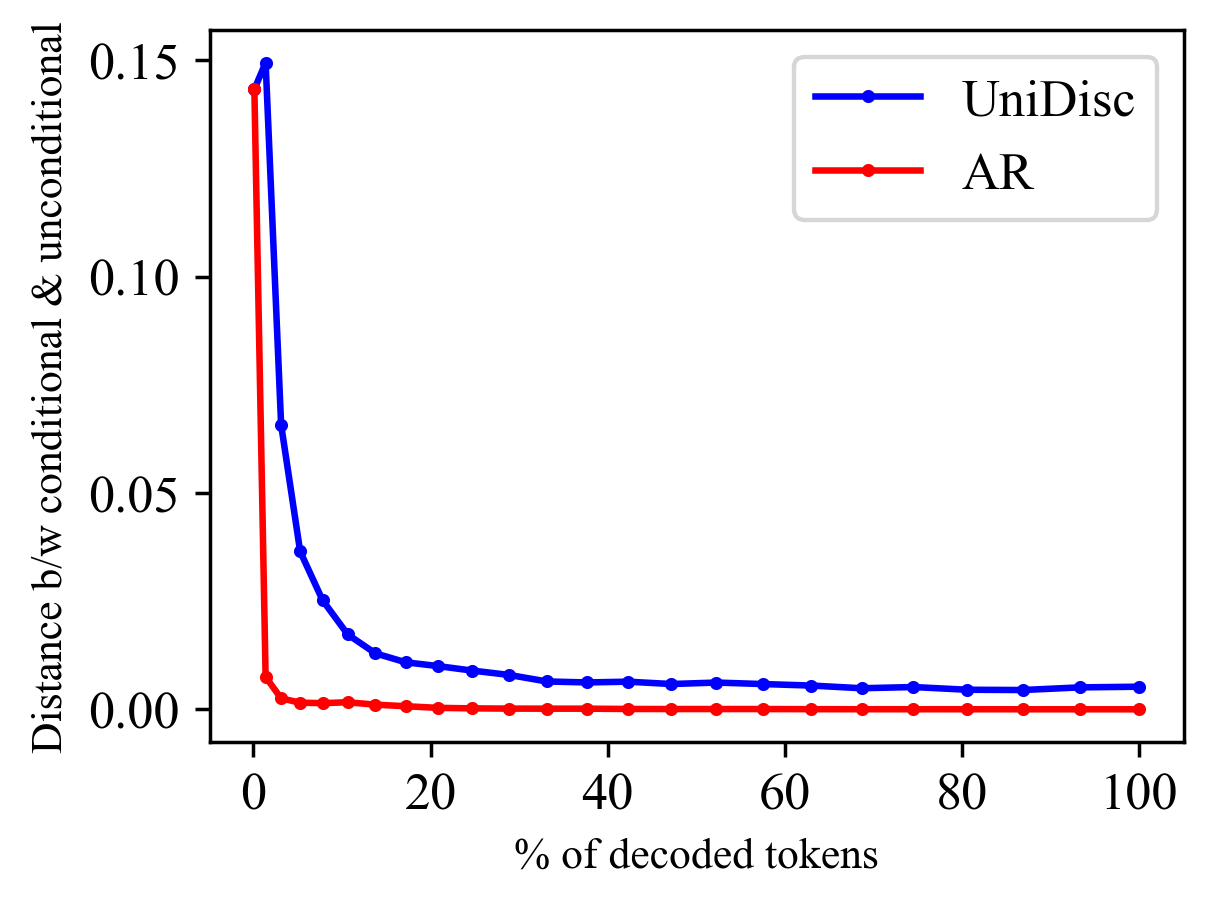
L2 distance between unconditional and conditional logits on currently masked tokens as sampling steps increase.
| Steps | CLIP Score |
|---|---|
| [1-3] | 0.301 |
| [12-14] | 0.293 |
| [22-24] | 0.283 |
| All (24) | 0.312 |
Comparing CLIP scores by applying CFG only on specific steps. This shows CFG has the most impact on the initial denoising steps (total steps = 24).
CFG significantly impacts the performance difference between UniDisc and Autoregressive model. To analyze this, we compare UniDisc with an AR model. The left figure shows the difference between conditional and unconditional predictions at various decoding stages. We observe that (a) the difference decreases as more tokens are decoded and (b) UniDisc maintains higher logit distances than AR throughout the process. We believe UniDisc's flexibility to generate tokens in any order allows it to keep a higher logit distance between unconditional and conditional predictions, thus allowing it to leverage CFG more effectively. The right table supports this, showing that applying CFG in just the first 3 steps achieves similar CLIP scores to applying it throughout all steps, while later-step CFG has minimal impact, which also correlates with the conditional and unconditional distance reducing as more tokens are decoded.
Qualitative Effect of Classifier-Free Guidance

Effect of classifier-free guidance in UniDisc, from left to right.
BibTeX
@article{swerdlow2025unidisc,
title = {Unified Multimodal Discrete Diffusion},
author = {Swerdlow, Alexander and Prabhudesai, Mihir and Gandhi, Siddharth and Pathak, Deepak and Fragkiadaki, Katerina},
journal = {arXiv preprint arXiv:2503.20853},
year = {2025},
doi = {10.48550/arXiv.2503.20853},
}